
Metadata enrichment – highly scalable data classification and data discovery
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively. This feature significantly increases the productivity of the data stewards who provide business context to data by ensuring data quality, usefulness and protection for broader consumption.
To take full advantage metadata enrichments, you’ll want to publish data assets, enriched with metadata‚ to a catalog where users can quickly find and access the right information. Ensuring the right business terms are assigned to data is the cornerstone for governance, as it defines what the business nature of the data is, and which policies and rules apply to its management and protection. Since business users want to search for data using business terminology with which they are familiar, it’s also key to the findability of data. If data is not well classified, this will impact the precision and recall of search results as well as the application of appropriate policies.
But how do your ensure that when a business user searches for data, the search goes beyond data silos to encompass your end-to-end data landscape? A data fabric is an architectural approach to simplify data access in an organization to facilitate self-service data consumption. Agnostic to data environments, processes, utility and geography while integrating end-to-end data management capabilities, a data fabric architecture can automate data discovery, governance and consumption, enabling enterprises to manage data as a product. With a data fabric, enterprises elevate the value of their data by providing the right data, at the right time, regardless of where it resides.
At the heart of our data fabric solution is a data catalog that powers intelligent, self-service discovery of data models and more in a cloud-based enterprise metadata repository, called IBM Watson Knowledge Catalog. By bringing together infrastructure, technical and business metadata using common workflows, users can apply necessary governance and related policies. Ultimately this tool help users know their data, trust their data, protect their data and consume their data through metadata enrichment.
The new metadata enrichment feature of Watson Knowledge Catalog allows users to enrich their data with data quality analysis, profiling and automatic assignment with one click, and to deliver quality data faster, kick start governance and scale business understanding in an integrated experience. Using standard Watson Knowledge Catalog connectivity that’ss seamlessly integrated into IBM Cloud Pak for Data projects, data’s term assignment is powered by machine learning that isn’t constrained to a single global model, and can vary at the project level. This approach supports a setup where teams can easily test and use new models without impacting other teams, allowing for organizations to scale business understanding of data and, when needed, manually adjust the outcome of automated jobs.
Some of the new capabilities of Watson Knowledge Catalog include:
Entirely revisited workflow and user experience
The workflow and user experience for discovering, enriching and publishing a large number of data assets from a source to a catalog has been entirely revisited. By separating the metadata import and the metadata enrichment processes, the new workflow better reflects the different user roles who typically perform these different steps.
Scalability and elasticity
Meta data enrichment can handle thousands of assets and their columns. With search and filters applied, users can now easily drill down find, enrich or curate their assets faster and kickstart the overall governance and quality programs.
Broad list of supported connections
Supported by an ever-growing list of natively supported connections, users can now connect to dozens of data sources.
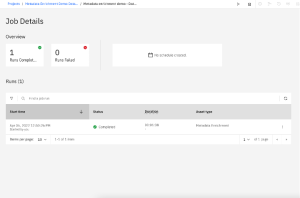
More control, scheduling and insight into the runs
Thanks to the use of the common jobs framework of Cloud Pak for Data, users can now schedule runs, have insight into all the current and past runs, get information on key statistics and be notified about the progress in a way which is consistent with other platform services.

You can now not only schedule discovery process, but also define data scope of re-run so it is limited only to new or modified assets.
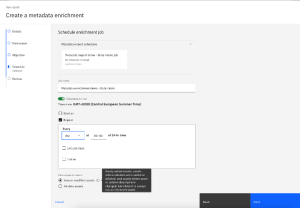
Support for BI reporting
With the reporting capability of Watson Knowledge Catalog, you can get insights from data, like seeing metrics related to the evolution of data dimensions, and export it to the external database.
Public API
With public API you can now manage metadata enrichment from external tools and workflows. See the official public APIs.
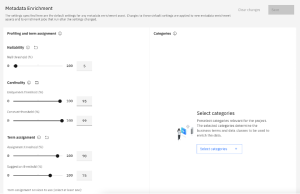
Project level settings
With the settings on the project level, there’s now a single-entry point to apply settings to multiple metadata enrichment assets at once. Users can set thresholds for the machine learning supported business term assignment and set categories that provide the scope of the business terms and data classes used.
Improved filters usability and bulk actions
With the broad set of filters, you can find relevant assets and columns much faster, than before and when needed bulk edit multiple columns or assets.
Read this article to see how to use metadata enrichment to implement data governance policies, and if you are interested in trying out the metadata enrichment feature of Watson Knowledge Catalog, check out the free trial.
The post Metadata enrichment – highly scalable data classification and data discovery appeared first on Journey to AI Blog.