
3 new steps in the data mining process to ensure trustworthy AI
Sometimes as data scientists, we are often so determined to build a perfect model that we can unintentionally include human bias into our models. Often the bias creeps in through training data and then is amplified and embedded in the model. If such model enters a production cycle it can have some serious implications directed by bias such as false prediction of credit score or health examination. Across various industries, regulatory requirements for model fairness and trustworthy AI aim to prevent biased models from entering production cycles.
How does a data architecture impact your ability to build, scale and govern AI models?
To be a responsible data scientist, there’s two key considerations when building a model pipeline:
- Bias: a model which makes predictions for people of different group (or race, gender ethnic group etc.) regularly discriminates them against the rest
- Unfairness: a model which makes predictions in ways that deprive, people of their property or liberty without visibility
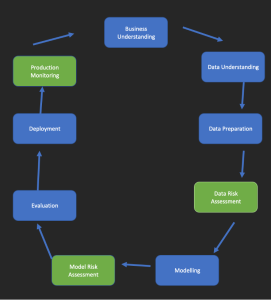
Detecting and defining bias and unfairness isn’t easy. To help data scientists reflect and identify possible ethical concerns the standard process for data mining should include 3 additional steps: data risk assessment, model risk assessment and production monitoring.

1. Data risk assessment
This step allows a data scientist to assess if there are any imbalances between different groups of people against the target variable. For example, we still observe that men are accepted on managerial position more frequently than women. But we all know that it’s illegal to offer a job based on gender, so to balance out the model you could argue that gender shouldn’t matter and could be removed. But what else could you impact by removing gender? Before acting this step should be examined with the right experts to determine whether the current checks are enough to mitigate potential bias in the model.
The goal of balancing the data is to mimic the distribution of data used in the production—this is to ensure the training data is as close as possible to the data used real time in production environment. So, while the initial reaction is to drop the biased variable, this approach is unlikely to solve the problem. Often variables are correlated and bias can sneak in through one of the correlated fields, living as a proxy replacement in the model. Therefore, all correlations should be screened before removing the bias to ensure its truly eliminated.
2. Model risk management
Model predictions have immediate and serious implications—in fact, they can change someone’s life entirely. If a model predicted that you have a low credit score it could affect everything in your life as you struggle to get credit cards and loans, find housing and get reasonable interest rates. Plus, if you don’t get a reason behind the low score, there’s no opportunity for improvement.
The job of data scientist is to ensure that a model gives the fairest outcome for all. If the data is biased, the model will learn from that bias and make unfair predictions. Black-box models provide great results, but with little interpretability and explainability making it impossible to check if there are any red-flags to ensure fairness. Therefore, a deep dive into model results is necessary. Data scientist needs to assess the trade-off of interpretability versus model performance and select models which best satisfy both requirements.
3. Production monitoring
Once a model is developed by data scientists it is often handed in to MLOps team. When the new model data is put in production it can bring a new possibility of bias or enhance the bias which was previously overlooked without proper monitoring in place. Production data can lead to drift in performance or consistency, and infuse bias into the model and data. It’s very important to monitor models by introducing proper alerts indicating deterioration of model performance and a mechanism for deciding when to retire a model that’s no longer fit for use using a tool like IBM Watson Studio. Again, data quality should be tracked by comparing the production data distribution to the data used to train the model.
Responsible data science means thinking about the model beyond the code and performance, and it is hugely impacted by the data you’re working with and how trustworthy it is. Ultimately, mitigating bias is a delicate, but crucial process that helps ensure that models follow the right human processes. This doesn’t mean you need to do anything new, but it’s important to rethink and reframe what we as data scientists already do to ensure it’s done in a responsible way.
To learn more about how data impacts your ability to create trustworthy AI visit our website.
The post 3 new steps in the data mining process to ensure trustworthy AI appeared first on Journey to AI Blog.